I have a few of the Geist Watchdog 15 devices in my data center. They do a good job monitoring, but getting data out of them isn’t as easy as it could be. Their latest firmware does introduce JSON over XML. Unfortunately, there is no way to do API calls to return certain time frames. You have to download the whole log file. Geist heavily uses the SNMP method to pull the information. While this is normally ok, but you do need the custom MIB file for the device which makes it a pain. I tried multiple ways to have Splunk grab the values from the device, but failed each time. With a deadline to produce a dashboard (it was 11pm and we had people visiting the office at 8am), I put my Google, Linux, and Splunk skills to a test.
First, let’s install the SNMP tools.
# yum install net-snmp net-snmp-devel net-snmp-utils
Let’s check where the default location of the MIBs are.
# net-snmp-config --default-mibdirs
/root/.snmp/mibs:/usr/share/snmp/mibs
We will want to copy the MIBs to the second location.
# cp /tmp/geist_bb_mib.mib /usr/share/snmp/mibs/geist_bb_mib.mib
(Source location will differ. The location /tmp/ was where I copied the file to)
Referencing the MIB Worksheet, we can find the OID for the items we want. In this script I selected: internalName, internalTemp, internalDewPoint, internalHumidity, tempSensorName, tempSensorTemp
Geist does not put the first period for the OID. In the worksheet they list internalName as 1.3.6.1.4.1.21239.5.1.2.1.3 where the SNMP call would be to .1.3.6.1.4.1.21239.5.1.2.1.3. We also need to reference the device ID for the OID at the end of the OID. The base for the Remote Temperature Sensor is .1.3.6.1.4.1.21239.5.1.4.1.3. To call the first Remote Temperature Sensor I would reference .1.3.6.1.4.1.21239.5.1.4.1.3.1 and the second Sensor is .1.3.6.1.4.1.21239.5.1.4.1.3.2.
To make the call to the device using SNMP, we will be using the snmpget command.
# /usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.4.1.3.1
-m all = Use all of the MIB files
-Ov = Print values only
-v 2c = Use version 2c
-c public = Use the public snmp string
10.10.10.10 = IP address of the Watchdog 15
.1.3.6.1.4.1.21239.5.1.4.1.3.1 = tempSensorName for Device 1
STRING: ExternalTempSensor1
We are almost there. Now to clear up the return to only give us the second part of the response.
# /usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.4.1.3.1 | awk '{print $2}'
ExternalTempSensor1
Great, now we are getting just the value. Time to tie the field and value together. Since the internal name is going to be the same but we are gathering multiple values, I am also adding the _temp so I am able to tell which field I am getting.
InternalName01=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.2.1.3.1 | awk '{print $2}'`
InternalTemp01=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.2.1.5.1 | awk '{print $2}'`
Section01=$InternalName01"_temp,"$InternalTemp01
echo $Section01
ExternalTempSensor1_temp,871
Almost there, now let’s add a date/time stamp.
InternalName01=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.2.1.3.1 | awk '{print $2}'`
InternalTemp01=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.2.1.5.1 | awk '{print $2}'`
Section01=$InternalName01"_temp,"$InternalTemp01
echo -e `date --rfc-3339=seconds`","$Section01
2016-05-16 22:07:57-05:00,ExternalTempSensor1_temp,871
I repeated the section for the different pieces of sensor data I wanted and ended up with a small script.
#!/bin/bash
InternalName01=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.2.1.3.1 | awk '{print $2}'`
InternalTemp01=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.2.1.5.1 | awk '{print $2}'`
Section01=$InternalName01"_temp,"$InternalTemp01
echo -e `date --rfc-3339=seconds`","$Section01
InternalDewPoint01=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.2.1.7.1 | awk '{print $2}'`
Section02=$InternalName01"_dewpoint,"$InternalDewPoint01
echo -e `date --rfc-3339=seconds`","$Section02
InternalHumidity01=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.2.1.6.1 | awk '{print $2}'`
Section03=$InternalName01"_humidity,"$InternalHumidity01
echo -e `date --rfc-3339=seconds`","$Section03
RemoteName01=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.4.1.3.1 | awk '{print $2}'`
RemoteTemp01=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.4.1.5.1 | awk '{print $2}'`
Section04=$RemoteName01"_temp,"$RemoteTemp01
echo -e `date --rfc-3339=seconds`","$Section04
RemoteName02=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.4.1.3.2 | awk '{print $2}'`
RemoteTemp02=`/usr/bin/snmpget -m all -Ov -v 2c -c public 10.10.10.10 .1.3.6.1.4.1.21239.5.1.4.1.5.2 | awk '{print $2}'`
Section05=$RemoteName02"_temp,"$RemoteTemp02
echo -e `date --rfc-3339=seconds`","$Section05
2016-05-16 22:12:57-05:00,Base_temp,873
2016-05-16 22:12:57-05:00,Base_dewpoint,620
2016-05-16 22:12:57-05:00,Base_humidity,43
2016-05-16 22:12:57-05:00,ExternalSensor1_temp,688
2016-05-16 22:12:57-05:00,ExternalSensor2_temp,717
I created a folder /opt/scripts/ and /opt/scripts/logs/. I placed the script in /opt/scripts/ and named it geist.sh. I set the script to be able to run with:
# chmod +x /opt/scripts/geist.sh
I then add it to the crontab.
# crontab -e
*/1 * * * * /opt/scripts/geist.sh >> /opt/scripts/logs/`date +”%Y%d%m”`_geist.log
You can verify that the script is set to run with:
# crontab -l
*/1 * * * * /opt/scripts/geist.sh >> /opt/scripts/logs/`date +"%Y%d%m"`_geist.log
Now we can log in to Splunk and add the log in to Splunk. After you log in, go to Settings and then Data inputs.
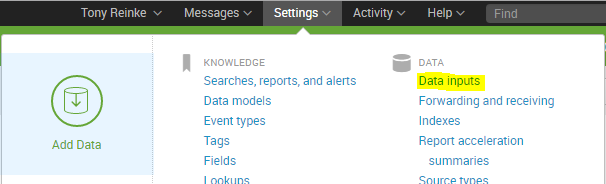
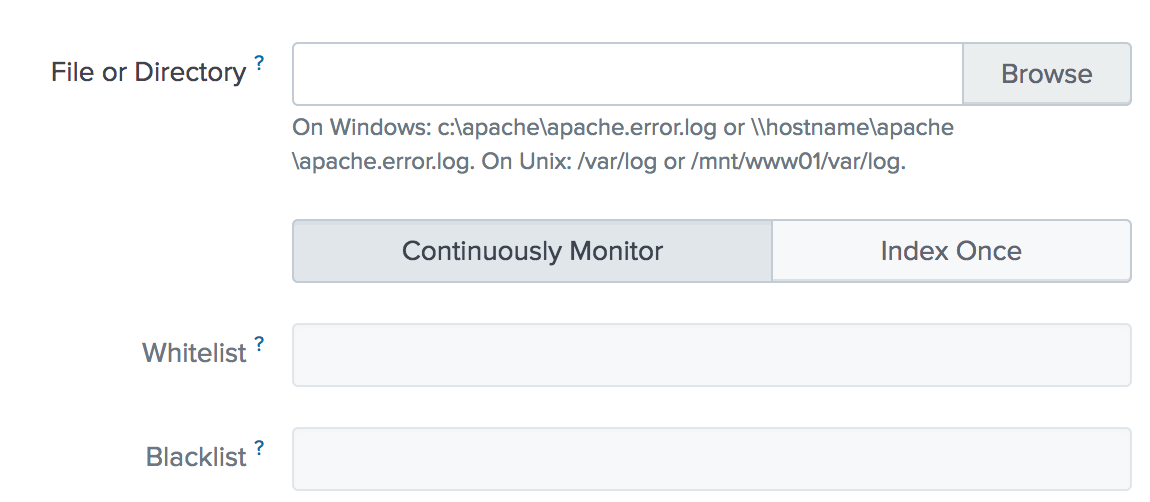
Under the Files & directories, click the Add new link.

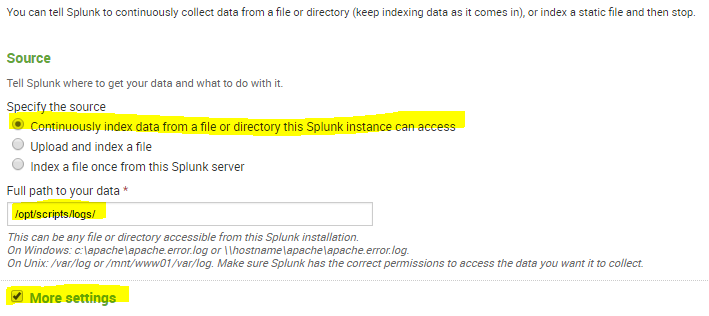
Under the Full path to your data, enter the path to the log file you are writing in the crontab. Check the box for the More settings option.
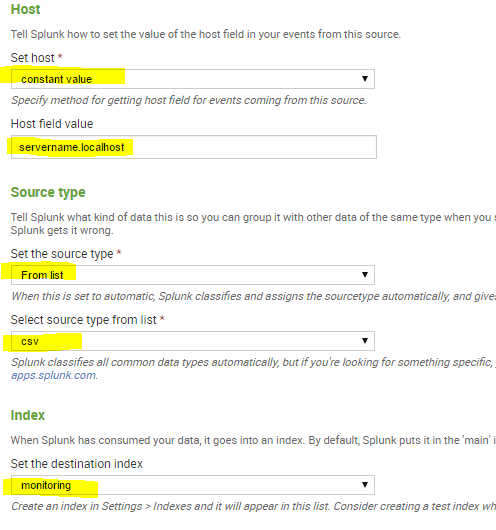
You can set the Host that will be indexed with your data. In the source type, select From list and then select csv. You then can select an index for the log files.
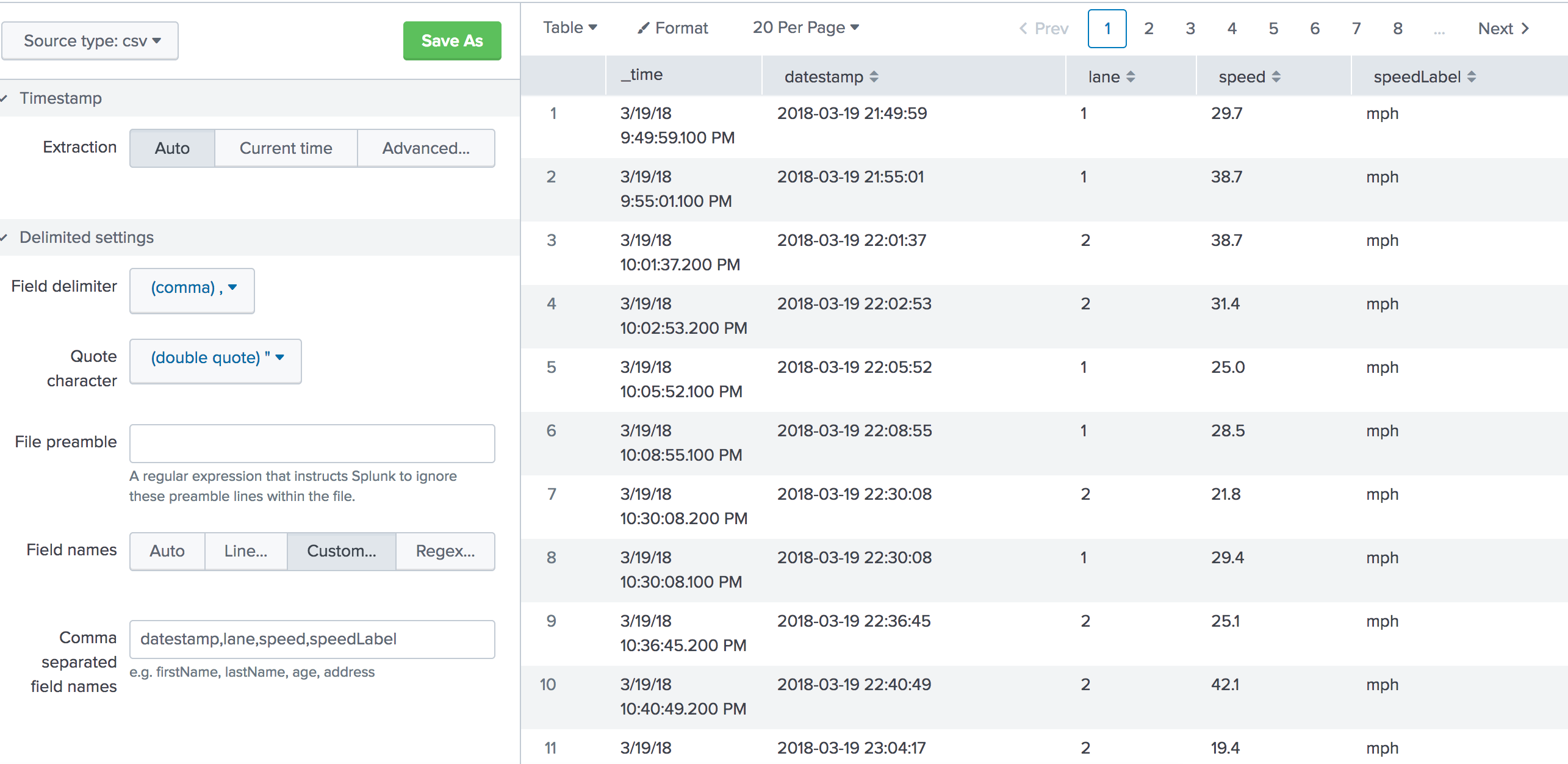
Now we will set up the field extractions. You will need to edit the props.conf and transforms.conf files. If you want to keep this in a certain application, change the file path to $SPLUNK_HOME/etc/apps/{appname}/local/props.conf.
# vi $SPLUNK_HOME/etc/system/local/props.conf
[csv]
REPORT-Geist = REPORT-Geist
# vi $SPLUNK_HOME/etc/system/local/transforms.conf
[REPORT-Geist]
DELIMS = ","
FIELDS = "DateTime","SensorName","SensorValue"
Restart Splunk and you should be able to search you SNMP values.
# $SPLUNK_HOME/bin/splunk restart